RethinkDB 2.1.5 performance & scaling report
In this article
This report describes a recent effort that the RethinkDB team took to measure our database product, RethinkDB, under different workloads and in different clustering configurations. We seek to provide a general overview of RethinkDB’s performance metrics for a variety of workloads and potential use cases. In this report some of the questions we’ll address include:
- What sort of performance can I expect from a RethinkDB cluster?
- How well does RethinkDB scale?
- Can I trade consistency for performance?
We’ll attempt to answer these questions by using workloads from the YCSB benchmark suite. You can learn more about YCSB here, and review the source code here. Expanding beyond the YCSB workloads we selected, we created an additional test which investigates scalability for analytic workloads.
In the results, we’ll see how RethinkDB scales to perform 1.3 million individual reads per second. We will also demonstrate how RethinkDB performs well above 100 thousand operations per second in a mixed 50:50 read/write workload - while at the full level of durability and data integrity guarantees. We performed all benchmarks across a range of cluster sizes, scaling up from one to 16 nodes.
Note: This performance report is based on RethinkDB version 2.1.5. It takes a large amount of effort to create a quality performance report that covers multiple use cases. In the future, we plan to update this report for subsequent releases of RethinkDB.
A quick overview of the results
We found that in a mixed read/write workload, RethinkDB with two servers was able to perform nearly 16K queries per second (QPS) and scaled to almost 120K QPS while in a 16-node cluster. Under a read only workload and synchronous read settings, RethinkDB was able to scale from about 150K QPS on a single node up to over 550K QPS on 16 nodes. Under the same workload, in an asynchronous “outdated read” setting, RethinkDB went from 150K QPS on one server to 1.3M in a 16-node cluster.
Finally, we used a MapReduce query to compute word counts across the whole data set. This test evaluates RethinkDB’s scalability for analytic workloads in a simplistic but very common fashion. These types of workloads involve doing information processing on the server itself versus typical single or ranged reads and writes of information processed at the application level.
Here we we show how RethinkDB scales up to 16-nodes with these various workloads:
Selecting workloads and hardware
YCSB comes with a variety of default workloads, but for the purposes of our testing we chose two of them to run against RethinkDB. Out of the YCSB workload options, we chose to run workload A which comprises 50% reads and 50% update operations, and workload C which performs strictly read operations. All documents stored by the YCSB tests contain 10 fields with randomized 100 byte strings as values, with each document totaling about 1 KB in size.
We used a port of YCSB based on our official Java driver and intend to submit a pull request for it in the near future. Our fork is available for review here.
Given the ease of scaling RethinkDB clusters across multiple instances, we deemed it necessary to observe performance when moving from a single RethinkDB instance to a larger cluster. We tested all of our workloads on a single instance of RethinkDB up to a 16-node cluster in varying increments of cluster size.
Hardware
In terms of hardware, we used the OnMetal offerings from Rackspace to run both RethinkDB server and RethinkDB client nodes. We used different hardware configurations for the server and client nodes as shown below:
| 1-16 RethinkDB servers | 8 RethinkDB clients |
|---|---|
| Rackspace OnMetal I/O | Rackspace OnMetal Compute |
| 2x Intel Xeon E5-2680 v2 CPU 2.8 GHz (2x10 cores) | Intel Xeon E5-2680 v2 CPU 2.8 GHz (10 cores) |
| 128 GB RAM | 32 GB RAM |
| 10Gbps Ethernet | 10Gbps Ethernet |
| Seagate Nytro WarpDrive BLP4-1600 storage |
Configuration
At the time of the test, we used RethinkDB 2.1.5 which was compiled from source on Ubuntu 14.04 LTS. During the performance test we used the RethinkDB Java driver with Oracle Java 1.8.0. A full list of configuration settings follows below:
- RethinkDB version 2.1.5
- Ubuntu 14.04
- RethinkDB cache size set to 64,000 MB per server, otherwise default parameters
- Oracle Java 1.8.0 on the client nodes
- The RethinkDB port of YCSB
Detailed results
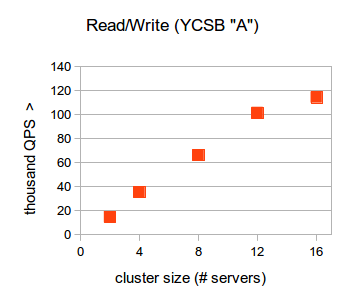
Workload A
- Simulates a mixed read/write workload with equally many writes as reads
- Query types: 50% single-document read ops, 50% single-document update ops
- Zipfian key access distribution
- 128 client connections per server
- Data is replicated to two servers, and sharded across all available servers
- Writes are performed with “hard” durability (wait for data to be on disk on both replicas)
- Performs 50 million operations in total
Our first workload from YCSB is workload A. It performs an equal number of get and update operations.
The data set generated by YCSB consists of 25 million documents, sized at 1 KB each. All data fits into the server cache in this scenario.
Reads and writes are performed by eight client servers, with 128 concurrent connections per database server. This means we have 128 connections with just a single RethinkDB server, and 2048 concurrent connections with a 16-node cluster. We used a replication factor of two per table, meaning each document was replicated to two separate servers.
RethinkDB achieves a throughput of 14.6K QPS with two servers, and scales near-linearly as servers are added to the cluster.
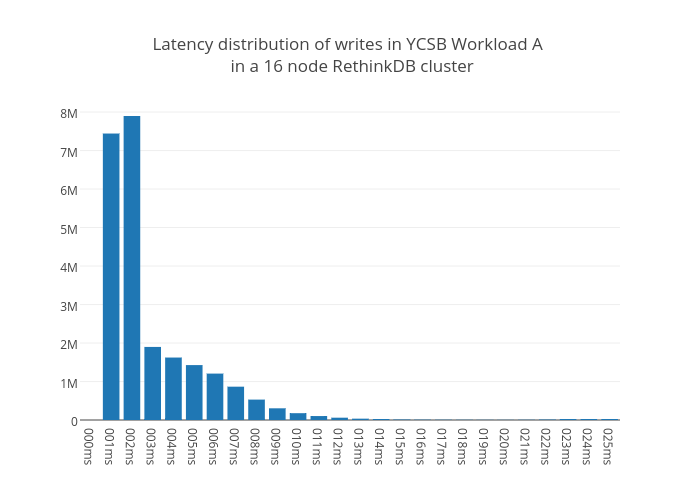
Latency is also an important metric to measure when testing performance. We found that in a 16-node cluster, the 95th percentile for Workload A query latencies is 26ms.
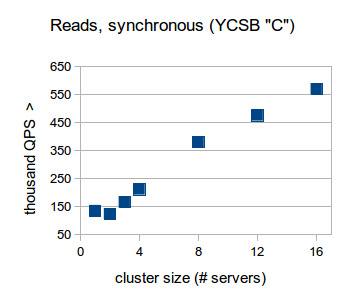
Workload C
- Simulates a read-only workload
- Query types: Single-document gets
- Zipfian key access distribution
- 128 client connections per server
- Data is replicated and sharded across all available servers
- In the “synchronous” test, we use the default
{readMode: ”single”}setting - In the “asynchronous” test, reads use the
{readMode: ”outdated”}setting - Performs 200 million operations in total
This workload exclusively performs read operations to retrieve individual documents from the database (YCSB workload C). In this workload, we use the same setup and data set as workload A above. Reads are also performed identically using 8 client servers with 128 concurrent connections per database server in the cluster.
We first tested this workload in the default configuration for RethinkDB which forbids stale reads. In this configuration, RethinkDB is able to perform 134.7K QPS on a single server. While the overhead of network communication between the servers becomes visible when increasing the cluster size from one to two servers, adding further servers to the cluster demonstrates the near-linear scalability of RethinkDB, up to over 500K QPS on 16 servers.
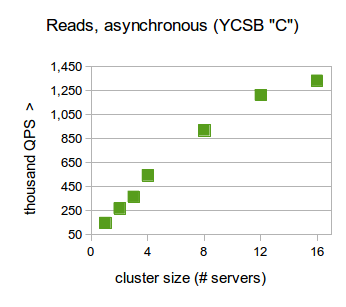
As a variation of this workload, we also tested scalability in the outdated read mode. In this mode, we make the compromise of a higher chance of slightly outdated read results for additional performance, as read operations can be handled directly by secondary replicas. A typical application that exemplifies this kind of access pattern would be an asynchronous cache.
RethinkDB demonstrates extremely high scalability in this configuration, reaching throughputs of well over a million queries per second. The slightly sub-linear scalability when going from 12 to 16 database servers is caused by the client servers’ CPUs getting saturated at these throughputs.
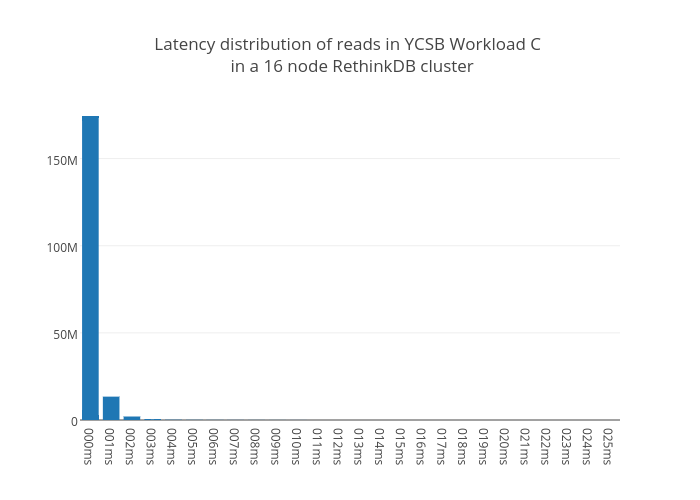
In terms of latency, we found that in a 16-node cluster and forbidding stale reads, the 95th percentile for latency is 3ms. When doing a heavy read workload, a large majority of reads fell between 0ms and 1ms which can be seen in the graph below.
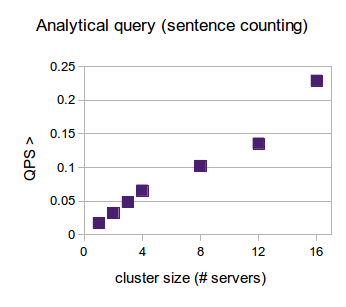
Analytic queries
- Tests the response time for analytic MapReduce queries involving string operations
- Query types: Count the total number of sentences over a single field: table.map(r.row(“field0”).split(“.”).count()).sum()
- We run one query at a time. Results show the average over five runs.
Finally, we demonstrate RethinkDB’s automatic query parallelization. Analytic queries are transparently distributed over servers in the cluster in a MapReduce-style pattern.
In this example, we count the number of sentences over the whole data set of 25 million documents based on one of the fields. We use the following exact query which utilizes the map and sum (reduce) functions of ReQL:
table.map( r.row("field0").split(".").count() ).sum()
We run this query five times for every cluster size and then calculate the average runtime. The results table below shows these averages.
| Nodes | 1 | 2 | 3 | 4 | 8 | 12 | 16 |
|---|---|---|---|---|---|---|---|
| Query Runtime (seconds) | 59 | 32 | 23 | 15 | 9.6 | 7.4 | 4.4 |
With a single server, our query takes 59 seconds to complete. The automatic query parallelization in RethinkDB results in practically linear scalability, as the same query is executed in just above 4 seconds on 16 servers. The graph, shown in the results overview section, demonstrates the inverse execution time (queries per second) of the query.
Conclusion
We wanted to provide a reasonably comprehensive RethinkDB test that covers a variety of different workloads. We chose to use the YCSB testing framework as a reliable and community-approved means of conducting rigorous testing on our database. We saw that all of the tests resulted in near-linear scalability as we moved from a single RethinkDB instance to a 16 node cluster. Although most of the tests resulted in performance metrics that suggest horizontal scalability, we know that there are plenty of improvements to make as the database evolves.
Ongoing
Near to the release of this performance report, we are excited to release RethinkDB 2.3 with plenty of new features. Rigorous performance testing, and properly publishing results is a very time-consuming process, but one we will conduct for future releases on an ongoing basis. We plan to publish our next set of metrics during the lifetime of the RethinkDB 2.3 release. We also would like to test RethinkDB performance when scaled to beyond a 16 node cluster during our next testing cycle. Going forward, we will include a summary of previous reports at the end of each report for comparison.
Notes
- We were fortunate enough to receive free credits from Rackspace to perform the majority of these tests and are very grateful for their contributions to open source software. All of Rackspace’s OnMetal offerings can be found here.
- We’d love to answer any questions you have about these tests. Come join us at http://slack.rethinkdb.com and feel free to ask more specific questions we don’t answer here by pinging @danielmewes or @dalanmiller.
- Recently, the team behind BigchainDB – a scalable blockchain database built on top of RethinkDB – has benchmarked RethinkDB on a 32-server cluster running on Amazon’s EC2. They measured throughput of more than a million writes per second. Their conclusion: “There is linear scaling in write performance with the number of nodes.” The full report is available at https://www.bigchaindb.com/whitepaper/
- We also recently contracted Kyle Kingsbury, known to the Internet as @aphyr, as an independent researcher to evaluate RethinkDB. He wrote a pair of blog posts on how he tested and confirmed RethinkDB clustering and consistency guarantees.