
RethinkDB 2.1.5 performance & scalability
 Daniel Alan Miller
Daniel Alan Miller
This report describes a recent effort that the RethinkDB team took to measure our database product, RethinkDB, under different workloads and in different clustering configurations. We seek to provide a general overview of RethinkDB’s performance metrics for a variety of workloads and potential use cases. In this report some of the questions we’ll address include:
- What sort of performance can I expect from a RethinkDB cluster?
- How well does RethinkDB scale?
- Can I trade consistency for performance?
We’ll answer these questions by using different workloads from the YCSB benchmark. You can learn more about YCSB here, and review the source code here. Expanding beyond the YCSB workloads we selected, we created an additional test which investigates scalability for analytic workloads.
In the results, we’ll see how RethinkDB scales to perform 1.3 million individual reads per second. We will also demonstrate how RethinkDB performs well above 100 thousand operations per second in a mixed 50:50 read/write workload - while at the full level of durability and data integrity guarantees. We performed all benchmarks across a range of cluster sizes, scaling up from one to 16 nodes.
Note: This performance report was based on RethinkDB version 2.1.5. It takes a large amount of effort to create a quality performance report that covers multiple use cases. In the future, we plan to update this report for subsequent releases of RethinkDB.
A quick overview of the results
We found that in a mixed read/write workload, RethinkDB with two servers was able to perform nearly 16K queries per second (QPS) and scaled to almost 120K QPS while in a 16-node cluster. Under a read only workload and synchronous read settings, RethinkDB was able to scale from about 150K QPS on a single node up to over 550K QPS on 16 nodes. Under the same workload, in an asynchronous “outdated read” setting, RethinkDB went from 150K QPS on one server to 1.3M in a 16-node cluster.
Finally, we used a MapReduce query to compute word counts across the whole data set. This test evaluates RethinkDB’s scalability for analytic workloads in a simplistic but very common fashion. These types of workloads involve doing information processing on the server itself versus typical single or ranged reads and writes of information processed at the application level.
Here we we show how RethinkDB scales up to 16 nodes with these various workloads:
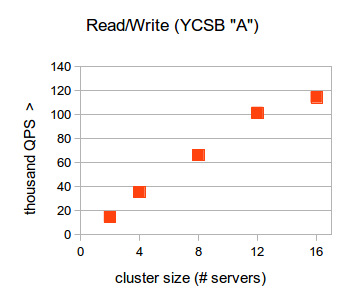
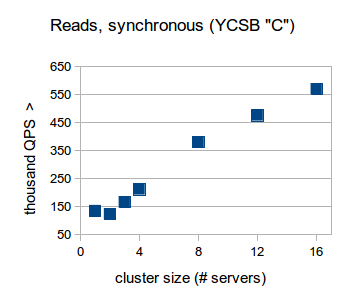
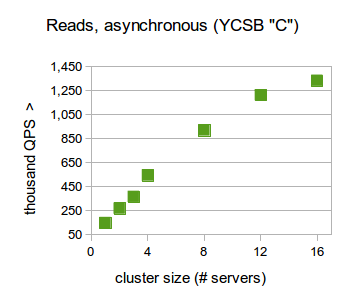
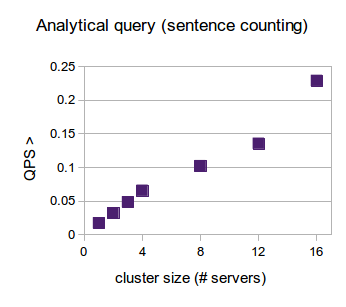
In the full report you can find the specifics of the tests and learn more about latency distributions as we scaled up to 16 server clusters for each workload.
See the full performance report </a>
Notes:
- Thank you to Rackspace for providing free credits to perform a majority of these tests. We are grateful for their contributions to open source software. All of Rackspace’s OnMetal offerings can be found here.
- We’d love to answer any questions you have about these tests. Come join us at https://join.slack.com/t/rethinkdb/shared_invite/enQtNzAxOTUzNTk1NzMzLWY5ZTA0OTNmMWJiOWFmOGVhNTUxZjQzODQyZjIzNjgzZjdjZDFjNDg1NDY3MjFhYmNhOTY1MDVkNDgzMWZiZWM and feel free to ask more specific questions we don’t answer here by pinging @danielmewes or @dalanmiller.
- Recently, the team behind BigchainDB – a scalable blockchain database built on top of RethinkDB – has benchmarked RethinkDB on a 32-server cluster running on Amazon’s EC2. They measured throughput of more than a million writes per second. Their conclusion: “There is linear scaling in write performance with the number of nodes.” The full report is available at https://www.bigchaindb.com/whitepaper/
- We also recently contracted Kyle Kingsbury, known to the Internet as aphyr, as an independent researcher to evaluate RethinkDB. He wrote a pair of blog posts on how he tested and confirmed RethinkDB clustering and consistency guarantees.