Getting started with RethinkDB and Python 3
 Chad Lung
Chad Lung
This post originally appeared on Giant Flying Saucer, Chad Lung’s blog.
I’ve been keeping an eye on RethinkDB for a while now and recently began working with it. There is a lot to like about RethinkDB like the ability to easily cluster and scale your deployment but what I’m going to focus on today is something called Changefeeds. I’ll start this blog article off with installing a development server running RethinkDB and then move onto a quick tutorial. From there we will look at Changefeeds.
Like some of my other articles I’ve created a Github repo with the scripts needed to get a Vagrant instance running a single RethinkDB node. Simply go to the repo, clone it, and follow the instructions.
Once the Vagrant RethinkDB server is running you’ll want to create a Python 3 project folder to work out of. To see how I usually setup my project folders you can see this article.
Make sure to install the RethinkDB Python client (version 1.14 and above works with Python 3):
$ pip install rethinkdb
At this point I’ll assume you have your Vagrant based RethinkDB server running and Python 3 project set up. Let’s start with a real simple example to create a new database and a table to test with.
Create a file called app.py and add the following to it:
import rethinkdb as r
from rethinkdb.errors import RqlRuntimeError
if __name__ == "__main__":
conn = r.connect('localhost', 28015)
try:
print(r.db_create("mydb").run(conn))
print(r.db("mydb").table_create("mytable").run(conn))
except RqlRuntimeError as err:
print(err.message)
finally:
conn.close()
You should see result similar to this when you run the code above:
{'dbs_created': 1, 'config_changes': [{'old_val': None, 'new_val': {'id': 'acb2a1b4-9880-42d3-ab17-07c0f00038a6', 'name': 'mydb'}}]}
{'tables_created': 1, 'config_changes': [{'old_val': None, 'new_val': {'id': '7b99e0b4-beb3-45a2-a286-0e5d04191f25', 'name': 'mytable', 'primary_key': 'id', 'durability': 'hard', 'db': 'mydb', 'shards': [{'primary_replica': 'rethinkdb1_jqi', 'replicas': ['rethinkdb1_jqi']}], 'write_acks': 'majority'}}]}
If you take a peek at the Web UI you should see the new database and table.
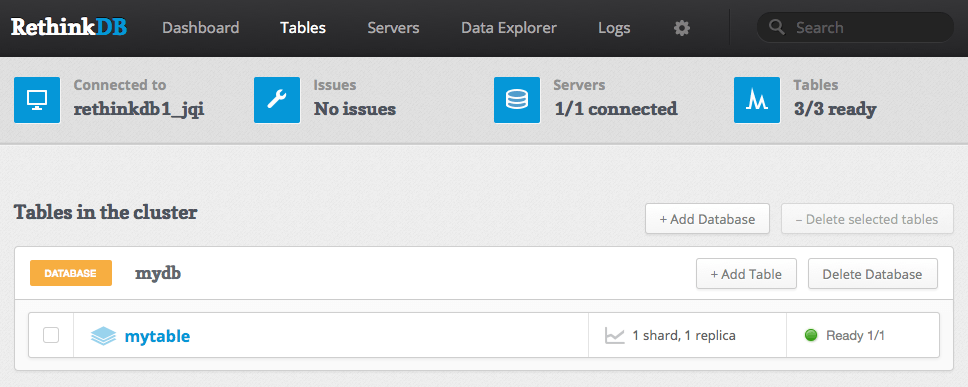
Adding new records is very simple and is done in a simple JSON format. Below I’ll add two records:
import rethinkdb as r
from rethinkdb.errors import RqlRuntimeError
if __name__ == "__main__":
conn = r.connect(host='localhost', port=28015, db='mydb')
try:
print(r.table("mytable").insert([
{
"stock": "IBM",
"close": 40,
"open": 38
},
{
"name": "Apple",
"close": 128,
"open": 129
}
]).run(conn))
except RqlRuntimeError as err:
print(err.message)
finally:
conn.close()
Note: The print statements I’ve added wrapping the calls are to
provide feedback in your console to let you see a little more of what is
going on.
In the code above you can see I’ve modified the connection slightly by adding in keywords and ensuring I’m using the correct database. If you don’t specify a database the default one will be used.To look at the new records you can query the contents of the table:
import rethinkdb as r
from rethinkdb.errors import RqlRuntimeError
if __name__ == "__main__":
conn = r.connect(host='localhost', port=28015, db='mydb')
try:
cursor = r.table("mytable").run(conn)
for record in cursor:
print(record)
except RqlRuntimeError as err:
print(err.message)
finally:
conn.close()
You should see output as such:
{'close': 128, 'open': 129, 'id': '7073881d-be30-4513-8ea6-3e360c475c70', 'name': 'Apple'}
{'close': 40, 'stock': 'IBM', 'open': 38, 'id': '17847249-f6ca-40e4-b2b4-6b2787963add'}
Obviously you can filter on a table. In this case we just had the two records in there but if there where more you would want to query what your looking for or use pagination which RethinkDB also supports.
I’m not going to delve any deeper into the query aspects of RethinkDB as they are very well documented with examples. What I want to move into now are Changefeeds. According to the RethinkDB documentation: “Changefeeds lie at the heart of RethinkDB’s real-time functionality. They allow clients to receive changes on a table, a single document, or even the results from a specific query as they happen.” Have you ever had to poll a database for changes? Perhaps run some code when a specific event happens? Changefeeds in RethinkDB make this trivial to capture and process these kinds of things.
Let’s hop into an example to explain this.
First, we will add a second table to the mydb database. The second table
will be called: mytable2 (not very creative, I know). Run the following
code:
import rethinkdb as r
from rethinkdb.errors import RqlRuntimeError
if __name__ == "__main__":
conn = r.connect('localhost', 28015)
try:
print(r.db("mydb").table_create("mytable2").run(conn))
except RqlRuntimeError as err:
print(err.message)
finally:
conn.close()
Now we will create a simple Python script that will populate some random values into the RethinkDB tables we created. I’ve added a short pause between the inserts as I want to buy some time so the second script can casually print these out for us rather than in one big rush of prints. The code looks like the following but don’t run it yet.
from random import choice
from string import ascii_uppercase, digits
from time import sleep
import rethinkdb as r
from rethinkdb.errors import RqlRuntimeError
if __name__ == "__main__":
conn = r.connect(host='localhost', port=28015, db='mydb')
try:
for x in range(10):
value1 = ''.join(choice(ascii_uppercase + digits) for _ in range(7))
r.table('mytable').insert({'somevalue': value1}).run(conn)
sleep(1)
value2 = ''.join(choice(ascii_uppercase + digits) for _ in range(7))
r.table('mytable2').insert({'something': value2}).run(conn)
sleep(1)
except RqlRuntimeError as err:
print(err.message)
finally:
conn.close()
So just a simple script to add values. Now, let’s add a second script to capture all the change events that will be triggered. To make this more fun we will use some multithreading and a queue. The code looks like:
from queue import Queue
from threading import Thread
from time import sleep
import rethinkdb as r
stream_queue = Queue()
def get_changes(table_name):
conn = r.connect(host='localhost', port=28015, db='mydb')
for change in r.table(table_name).changes().run(conn):
stream_queue.put(change)
if __name__ == "__main__":
thread1 = Thread(target=get_changes, args=("mytable",))
thread2 = Thread(target=get_changes, args=("mytable2",))
thread1.setDaemon(True)
thread2.setDaemon(True)
thread1.start()
thread2.start()
while True:
item = stream_queue.get()
print(item)
stream_queue.task_done()
sleep(0.1)
The magic is in the get_changes method. That will run and report any
changes that happen within the table specified. Keep in mind these changes
don’t just have to be inserts, they can be almost anything and you can
even set filters. Run the above code and then in another console run the
script to populate the values. You should see the changes as they happen
every second:
{'new_val': {'somevalue': 'BM7WR81', 'id': 'c0bd00a6-4538-4b18-88f4-d726986deedb'}, 'old_val': None}
{'new_val': {'id': '73adeb5f-5e15-44e5-a666-bd5fa2437963', 'something': 'VKIG966'}, 'old_val': None}
{'new_val': {'somevalue': '6E2Y3G3', 'id': '789a1b1d-f73b-43b6-9fb7-6f92c2b28dac'}, 'old_val': None}
{'new_val': {'id': '52828ae8-b235-441f-b8c7-cae0e68af0d0', 'something': 'T7LWRQE'}, 'old_val': None}
{'new_val': {'somevalue': 'TQW23I6', 'id': '75b8646e-b6d3-42f0-b1a4-5de800646700'}, 'old_val': None}
{'new_val': {'id': '39574a43-02a3-46c0-87b8-f0cb157709a5', 'something': 'F4PPR9N'}, 'old_val': None}
{'new_val': {'somevalue': '6YW1CEK', 'id': 'b357a1b8-965a-42c4-9bac-d3ddecd241f8'}, 'old_val': None}
{'new_val': {'id': 'c7994343-3883-44fc-a1e9-5d5419618538', 'something': 'QLVVGZN'}, 'old_val': None}
{'new_val': {'somevalue': 'C8IID00', 'id': 'c14429a3-8340-4fab-bf63-1b4cbc9f82e6'}, 'old_val': None}
{'new_val': {'id': '3ddad286-75ef-47ca-988b-e84b3ab937e3', 'something': '6IHPLOX'}, 'old_val': None}
{'new_val': {'somevalue': 'UMN862S', 'id': '9b5f9a8f-1400-471b-b508-b44fd3a2a5c9'}, 'old_val': None}
{'new_val': {'id': '74abb4bd-3f20-446d-820a-90af5cdff32b', 'something': 'Z5RV2T9'}, 'old_val': None}
{'new_val': {'somevalue': 'PL2RXEH', 'id': '0bf272c4-d51c-42ee-8d8d-381022c37521'}, 'old_val': None}
{'new_val': {'id': 'ad255aaf-8453-4cff-af2c-b7c259ceecaa', 'something': 'EKMXBSF'}, 'old_val': None}
{'new_val': {'somevalue': '7FZJ37B', 'id': '5d8c9026-c646-41c9-8e86-f190fd246cf6'}, 'old_val': None}
{'new_val': {'id': '510fdbe0-8563-48bc-be9b-2690ad702453', 'something': 'OQGF2V9'}, 'old_val': None}
{'new_val': {'somevalue': 'KRQBCWL', 'id': '6754bb3f-0d48-4a6e-9508-83ab805013b5'}, 'old_val': None}
{'new_val': {'id': '22d3f7e6-c2e4-4c96-91e4-9206d509bfb3', 'something': 'AUON28Q'}, 'old_val': None}
{'new_val': {'somevalue': 'Q3KPFVF', 'id': 'ac631fb7-077d-41f0-8842-1439fae8d79e'}, 'old_val': None}
{'new_val': {'id': 'a7905d8d-a522-4ad1-84d4-3ecb1b6d1684', 'something': 'A9HZ3UO'}, 'old_val': None}
Let’s filter on only capturing values in one of the tables that exceed the value 5 and in the other table we only want to see changed values below the value 5. To do this we need to modify the script that does the population:
from time import sleep
import rethinkdb as r
from rethinkdb.errors import RqlRuntimeError
if __name__ == "__main__":
conn = r.connect(host='localhost', port=28015, db='mydb')
try:
for x in range(10):
r.table('mytable').insert({'counter': x}).run(conn)
sleep(1)
r.table('mytable2').insert({'counter': x}).run(conn)
sleep(1)
except RqlRuntimeError as err:
print(err.message)
finally:
conn.close()
Next we change the code listening for the changefeed data with the appropriate filters:
from queue import Queue
from threading import Thread
from time import sleep
import rethinkdb as r
stream_queue = Queue()
def get_values_above_five(table_name):
conn = r.connect(host='localhost', port=28015, db='mydb')
for change in r.table(table_name).changes().filter(
lambda change: change['new_val']['counter'] > 5).run(conn):
stream_queue.put(change)
def get_values_below_five(table_name):
conn = r.connect(host='localhost', port=28015, db='mydb')
for change in r.table(table_name).changes().filter(
lambda change: change['new_val']['counter'] < 5).run(conn):
stream_queue.put(change)
if __name__ == "__main__":
thread1 = Thread(target=get_values_above_five, args=("mytable",))
thread2 = Thread(target=get_values_below_five, args=("mytable2",))
thread1.setDaemon(True)
thread2.setDaemon(True)
thread1.start()
thread2.start()
while True:
item = stream_queue.get()
print(item)
stream_queue.task_done()
sleep(0.1)
Note: The above code is terse and verbose but the point I want to show here is filtering on two different things per thread. Obviously the code can be enhanced easily.
The results will be similar to this:
{'new_val': {'id': '64b43c33-b2e0-4104-98bb-2e4379d686e7', 'counter': 0}, 'old_val': None}
{'new_val': {'id': '9de5fc01-5e3f-4f42-af70-ee7c7e5cfdd9', 'counter': 1}, 'old_val': None}
{'new_val': {'id': 'ef94f158-ce8e-4973-9783-a0c917e84324', 'counter': 2}, 'old_val': None}
{'new_val': {'id': 'ab26b334-c492-4f38-998b-b0b814cf8ae5', 'counter': 3}, 'old_val': None}
{'new_val': {'id': '81c4c71f-4375-4b8e-98c4-56250e35673f', 'counter': 4}, 'old_val': None}
{'new_val': {'id': '001de627-6810-4604-9835-88753d91a9c8', 'counter': 6}, 'old_val': None}
{'new_val': {'id': 'f6673f59-5e4e-45ff-971f-cefe6bbf88c0', 'counter': 7}, 'old_val': None}
{'new_val': {'id': 'd11ce6c2-b2cd-4018-a7d5-837b7aaf98ff', 'counter': 8}, 'old_val': None}
{'new_val': {'id': 'a01f5604-cd5b-4eec-858d-152da7206b06', 'counter': 9}, 'old_val': None}
You can see 5 wasn’t printed out since we specified < 5 and > 5 for our
filters.
This is just the tip of the RethinkDB iceberg. Their docs are some of the best I’ve seen for a project and have a lot of clear examples. Be sure to check out the 10 minute guide as well as the simple Flask Todo tutorial.