RethinkDB 1.7: hot backup, atomic set and get, 10x insert performance improvement
 Slava Akhmechet
Slava Akhmechet
We are happy to announce RethinkDB 1.7 (Nights of Cabiria). Download it now!
This release includes the following features and improvements:
- Tools for CSV and JSON import and export
- Support for hot backup and restore
- ReQL support for atomic set and get operations
- A powerful new syntax for handling nested documents
- Greater than 10x performance improvement on document inserts
- Native binaries for CentOS / RHEL
- A number of small ReQL improvements (explained below)
See the full list of over 30 bug fixes, features, and enhancements.
Etienne Laurin (@atnnn), an engineer at RethinkDB, introduces these new features in this one-minute video:

Upgrading to RethinkDB 1.7? Make sure to migrate your data before upgrading to RethinkDB 1.7.
Import and export
Two extremely common use cases among RethinkDB users are to import existing JSON and CSV datasets into the database, or to export RethinkDB data as JSON or CSV to be used by another system. While it’s pretty simple to write quick import and export scripts using ReQL drivers, we didn’t want new users to keep replicating this work, so we included standardized import and export tools into RethinkDB 1.7.
You can import and export data as follows:
# Import a JSON document into table `users` in database `my_db`
$ rethinkdb import -c HOST:PORT \ # database host and port
-f user_data.json \ # file to import
--table my_db.users # table to import the data into
# Export a table into a CSV file
$ rethinkdb export -c HOST:PORT \ # database host and port
-e my_db.users \ # only export the `users` table in database `my_db`
--format csv \ # export into CSV format
--fields first_name,last_name,address # `--fields` is mandatory when exporting into CSV
- See this gist for more information on how to use
importandexportcommands. - Run
rethinkdb import --helpandrethinkdb export --helpfor full documentation.
Hot backup and restore
RethinkDB 1.7 also ships with dump and restore commands that allow easily
doing hot backups on a live cluster. Back up your data as follows:
# Dump the data from a RethinkDB cluster (placed in a file
# rethinkdb_dump_DATE_TIME.tar.gz by default)
$ rethinkdb dump -c HOST:PORT
Since the backup process is using client drivers, it automatically takes advantage of the MVCC functionality built into RethinkDB. It will use some cluster resources, but will not lock out any of the clients, so you can safely run it on a live cluster.
You can reimport the data back into a running cluster as follows:
# Reimport an earlier dump
$ rethinkdb restore -c HOST:PORT rethinkdb_dump_DATE_TIME.tar.gz
The dump and restore commands are built on top of import and export, and
operate on tar.gz archives of JSON documents (along with additional table
metadata). You can run rethinkdb dump --help and rethinkdb restore --help
for more information.
Atomic set and get
ReQL was always designed to support arbitrary atomic modification operations of documents. For example, you could increment a counter as follows:
r.table('videos').get(id).update({ views: r.row('views').add(1) })
However, until the 1.7 release it wasn’t possible to atomically get back the
result. We’ve now introduced an optional return_vals argument for single-row
modification operations. If you set it to true, you’ll atomically get back the
old and new versions of the document from the server:
r.table('videos').get(id).update({ views: r.row('views').add(1) }, {return_vals: true })
// returns { replaced: 1,
// vals: [{old_val: {..., views: N, ...},
// new_val: {..., views: M, ...}}]}
This functionality is similar to MongoDB’s findAndModify and Redis’s atomic commands, and allows gracefully handling a variety of sophisticated use cases.
- See this gist to learn how to use the atomic set-and-get functionality to implement a simple publish-subscribe queueing system.
10x insert performance improvement
Prior to this release, many people pointed out that RethinkDB has poor insert performance. We did a lot of investigation and were able to include fixes in this release that result in greater than 10x insert performance improvement. There were multiple causes of poor performance on data insertion:
- We switched Python, Ruby, and Javascript clients to use significantly faster protocol buffer libraries that have C++ backends (see issues #1025, #1026, and #1027 for more details).
- Even with faster protocol buffer libraries, protocol buffer serialization is
slower than JSON serialization. The
insertcommand now automatically usesr.jsonwhenever possible (see issue #887 for more details). - The RethinkDB storage engine issued a flush command to operating systems more often than necessary for safety. This is now fixed (see issue #520).
The benchmark was done as follows:
- Machine spec
- Processor: Intel Core i7-2760QM CPU @ 2.40GHz x 8
- Memory: 11.7 GiB
- Kernel: 3.2.0-49 64bit
- OCZ Vertex 120GB SSD
- Benchmark configuration:
- 10,000 documents
- Inserting batches of 10 documents at a time
- Default server settings (hard durability,
noreplyturned off)
Here are the results of performance tests for small (120 byte) documents:
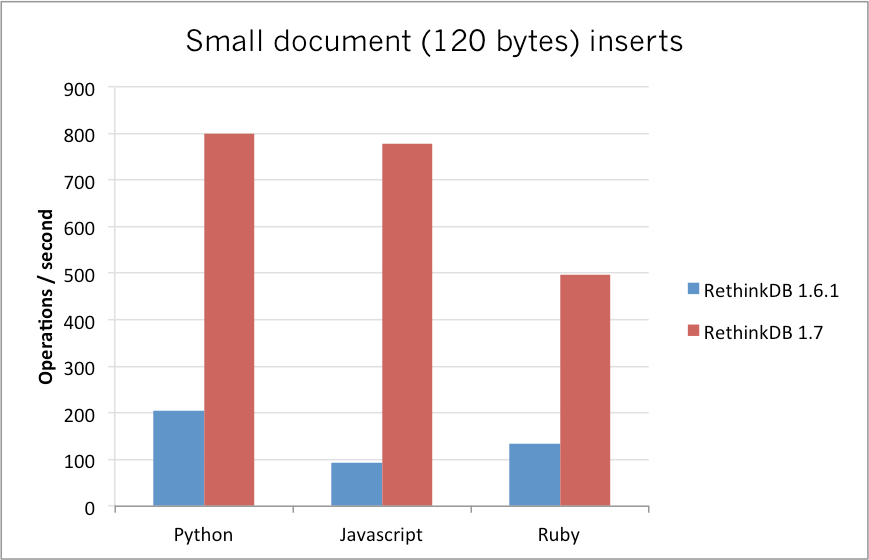
And here are the results of performance tests for large (8 KB) documents on the same machine:
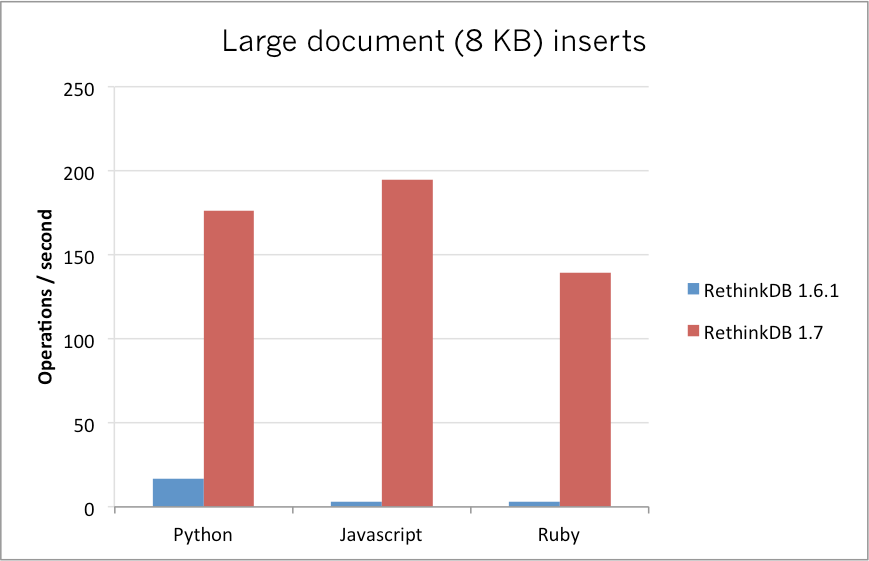
Note: these aren’t scientific benchmarks, it’s just something we put together to demonstrate improvements. You should be able to experience the improvements on most insert workloads in RethinkDB 1.7. We’re working on thorough and scientific benchmarks, and will be publishing them soon.
Other enhancements
In addition to the changes above, we made a number of other enhancements that make some ReQL use cases a lot more pleasant:
- The
getFieldcommand now works on sequences (see this gist for details). - The
getAllcommand now allows querying multiple keys (see this gist for details). - The
pluckcommand now has syntax for manipulating nested objects (see this gist for details).
Looking forward to 1.8
We’re starting to work on the 1.8 release. It’s scheduled to include
extensive improvements to nested attributes handling (see issues #872 and
#1094), native support for date operations (see #977), and improvements
to the groupBy and groupedMapReduce commands (see #977).
After the 1.8 release is out, we expect to focus our efforts almost entirely on performance and scalability as we gear up for a production-ready release of RethinkDB. If you have comments about the roadmap, we’d love to hear from you!