
RethinkDB 1.16: cluster management API, realtime push
 Ryan Paul
Ryan Paul
Today, we’re happy to announce RethinkDB 1.16 (Stand by Me). Download it now!
The 1.16 release is a precursor to the upcoming 2.0 release, and is the biggest RethinkDB release to date with over 300 enhancements. This release includes two exciting new features: a comprehensive API for large cluster management, and realtime push functionality that dramatically simplifies the development of realtime web apps.
The cluster management API builds upon the sharding and replication functionality in previous versions of RethinkDB, and adds complete control and visibility into the operational details. It includes:
- A
reconfigurecommand to manipulate shards and replicas - A
rebalancecommand to balance data across shards on demand - A writable
table_configsystem table that gives precise control of sharding and replication configuration - A
table_statussystem table that gives detailed visibility into the state of every table in the cluster - A
statssystem table that gives access to comprehensive statistics - A writable
jobssystem table that gives control of the background jobs running in the cluster cluster_config,current_issues,db_config,logs,server_config, andserver_statussystem tables for additional control and visibility
The realtime push functionality is the start of an exciting new database access
model – instead of polling the database for changes, the developer can tell
RethinkDB to continuously push updated query results to applications in
realtime. We dramatically expanded the changes command to support the
following queries:
r.table(TABLE).get(ID).changes()r.table(TABLE).between(LEFT_ID, RIGHT_ID).changes()r.table(TABLE).filter(CONDITION).changes()r.table(TABLE).map(TRANSFORMATION).changes()r.table(TABLE).orderBy(CONDITION).limit(NUMBER).changes()r.table(TABLE).min(INDEX).changes()r.table(TABLE).max(INDEX).changes()

If you’re upgrading from previous versions, you may need to recreate your indexes.
Note: In RethinkDB 1.16 the rethinkdb admin command has been removed and
replaced with the new ReQL management API.
Programmatic cluster management
In previous versions of RethinkDB, some cluster management operations were available through the web interface and others were accessible through a specialized command line tool. RethinkDB 1.16 unifies all of the cluster management capabilities supported by the database and exposes them via a simple ReQL API.
We worked with users running large RethinkDB deployments to design the new cluster management API, and settled on three major design goals:
- All cluster management and monitoring functionality should be accessible programmatically
- Performing common operations should be simple and intuitive
- Detailed control and visibility should be available, and should be as simple as possible
As of this release, you can now perform cluster management tasks with ReQL queries in a REPL or with scripts written in any programming language that has a RethinkDB driver.
Sharding and replication
ReQL’s createTable command now accepts two new optional arguments: shards
and replicas. If you specify the sharding and replication factor, the
database will automatically partition and distribute the table. You can modify
the settings later by calling the reconfigure command on the table object.
You can also optionally use tagging to explicitly control how many replicas are
assigned to individual servers:
r.table('users').reconfigure(
shards=2,
replicas={'us_west':3, 'us_east':2},
primary_replica_tag='us_east'
).run(conn)
New sharding web interface
The web UI has been completely rebuilt to take advantage of the new ReQL clustering API. We’ve also updated the sharding and replication web interface to give administrators more visibility and control:
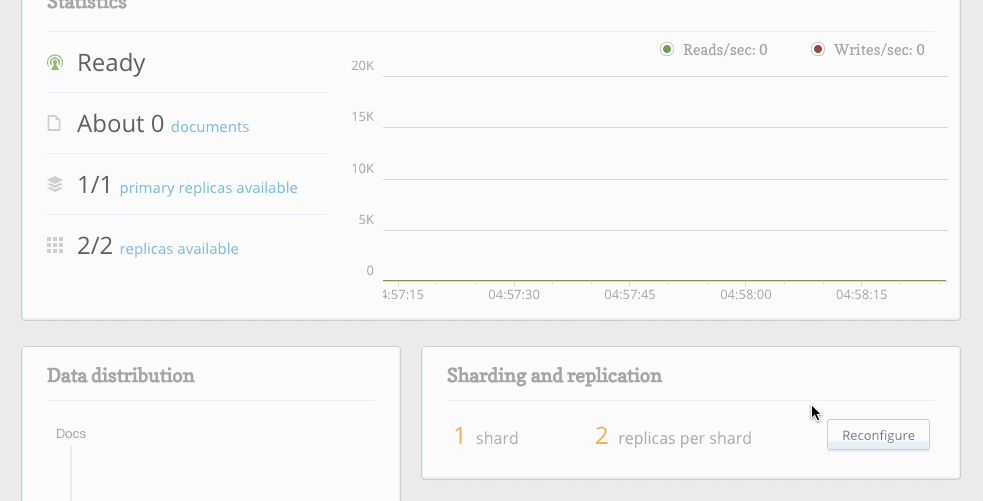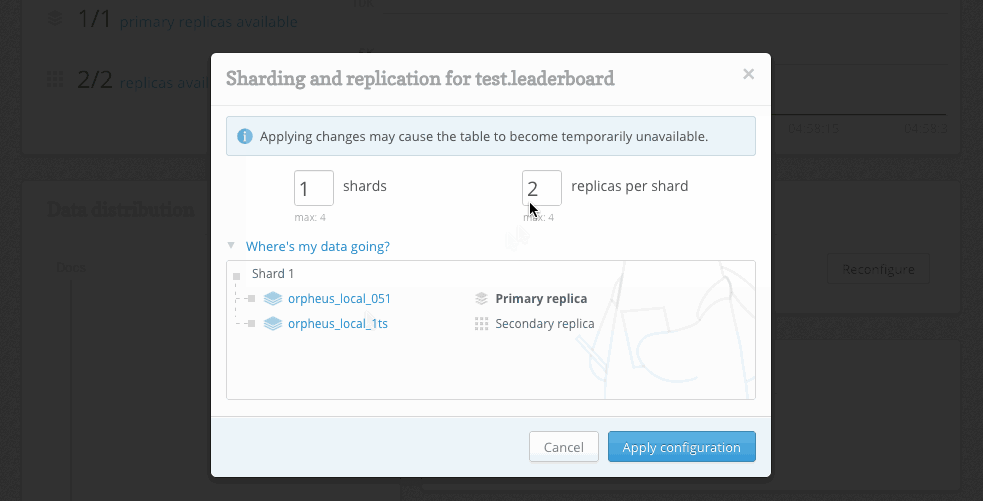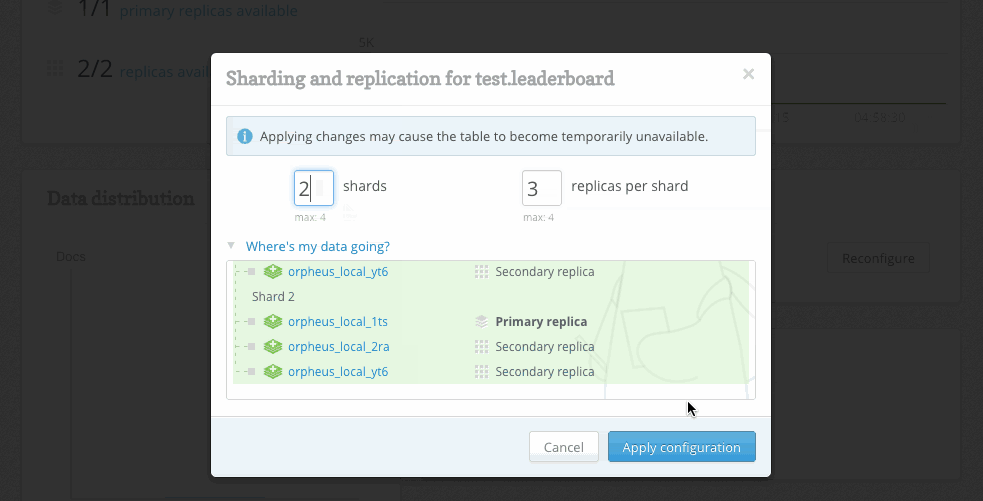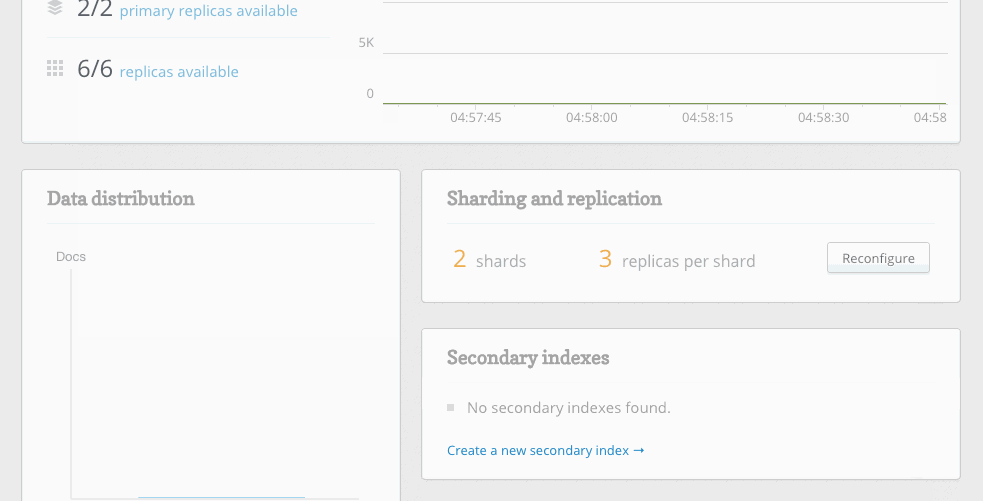
As you change the number of shards and replicas, RethinkDB presents a visual diff of the current and proposed cluster configurations. Administrators can see exactly where the data will go before approving the proposed plan.
Precise control
RethinkDB 1.16 introduces a number of system tables that expose database settings and the internal state of the cluster. You can query and interact with system tables using conventional ReQL commands, just like you would with any other RethinkDB table.
To exercise granular control over sharding and replication, you can use the new
table_config table. Each document in table_config represents a different
table in your database cluster, and includes details on sharding and
replication settings. A table_config document typically looks like this:
{
id: "31c92680-f70c-4a4b-a49e-b238eb12c023",
name: "tablename",
db: "test",
primary_key: "id",
shards: [
{primary_replica: "a", "replicas": ["a", "b"]},
{primary_replica: "b", "replicas": ["a", "b"]}
],
write_acks: "majority",
durability: "hard"
}
When you modify those properties using the update command, the cluster will
apply the new settings. You can also use this approach to tweak some advanced
table settings for behaviors like durability.
The high-level reconfigure command is a porcelain command on top of the
table_config system table. When you call reconfigure, the command compiles
high-level settings like the number of shards and replicas into a concrete
configuration document, and updates the appropriate document in the
table_config system table. You can also call reconfigure with a dry_run
optional argument to see the proposed configuration before applying it.
Using the high-level configuration commands and the finer-grained control
offered by table_config, you can create elaborate scripts that automate much
of your cluster configuration in a testable, repeatable way.
Monitoring
Alongside the configuration table, RethinkDB 1.16 also introduces several new read-only tables that you can query to get detailed information about the status of the cluster:
- The
table_statustable contains information about table availability. You can see if the table is ready for reads and writes and you can see the status of all of the table’s shards. - The
server_statustable shows the status and availability of individual servers within your RethinkDB cluster. Each document in the table represents a single RethinkDB server instance. It shows network configuration details, the process PID, and other administrative information. - The
statstable exposes detailed statistics that reflect the current state of servers, tables, and your cluster. You can see queries, reads, and writes per second, the number of active client connections, and other relevant statistics.
Job control
Another much-anticipated feature in RethinkDB 1.16 is support for managing
long-running operations. The new jobs table shows all of the background tasks
and queries in progress on your cluster. A typical document in the jobs table
might look like this:
{
"duration_sec": 0.00759,
"id": ["query", "3f6d08ae-d643-44b3-b643-e2812bfbbf93"],
"info": {"client_address":"::1", "client_port":56751},
"servers": ["batman_4rl"],
"type":"query"
}
If you want to terminate a query, simply delete the corresponding row from the table:
r.db('rethinkdb').table('jobs').get(["query", "3f6d08ae-d643-44b3-b643-e2812bfbbf93"]).delete()
Realtime push
Instead of polling the database for changes, you can now tell RethinkDB to continuously push updated query results to applications in realtime. This is the start of an exciting new database access model that should make building modern, realtime apps dramatically easier.
For example, suppose you’re building a realtime leaderboard for a game. You can get started with the database by using a familiar request-response query paradigm:
r.table('gameplays').orderBy(r.desc('score')).limit(5).run(conn)
As of RethinkDB 1.16, you can also ask the database to push changes to your app every time a gameplay that modifies the leaderboard is recorded in the database:
r.table('gameplays').orderBy(r.desc('score')).limit(5).changes().run(conn)
The first result of the query is just the top five gameplays. However, when the
developer tacks on the changes command, RethinkDB will keep the cursor open,
and push updates onto the cursor any time a relevant change occurs in the
database. The expanded changes command works on a wide variety of queries:
r.table(TABLE).get(ID).changes()r.table(TABLE).between(LEFT_ID, RIGHT_ID).changes()r.table(TABLE).filter(CONDITION).changes()r.table(TABLE).map(TRANSFORMATION).changes()r.table(TABLE).orderBy(CONDITION).limit(NUMBER).changes()r.table(TABLE).min(INDEX).changes()r.table(TABLE).max(INDEX).changes()
It also includes bells and whistles like latency awareness, that make building
realtime apps much more convenient. For example, if the query results change
too quickly and you don’t want to update the DOM more frequently than every
fifty milliseconds, you can tell changes to squash updates on a fifty
millisecond window, and the database will take care of aggregating diffs and
removing duplicates:
r.table('projects').get(PROJECT_ID).changes(squash=0.05).run(conn)
To learn more about how the changes command can make building
realtime apps dramatically easier, read our post
“Advancing the realtime web”.
Realtime monitoring
The new features in the 1.16 release can be used together in composable ways. For example, you can attach changefeeds to queries performed on the system monitoring tables in order to get live updates about the state of the cluster.
For example, if you want to create an animated line graph of operation statistics for all tables in your production database, you could set up a feed on the internal statistics table to monitor the RethinkDB cluster itself:
r.db('rethinkdb').table('stats').filter({ 'db': 'prod' }).changes()
You can set up changefeeds on other system tables like jobs, logs, and
server_status to get a realtime stream of updates on the state of the
cluster.
More improvements
There are many other exciting improvements in this release:
- A new
rangecommand that generates a range of numbers - A new
waitcommand that lets you wait for a table to become ready - A new
toJsonStringcommand that converts a datum to a JSON string - The
mapcommand is now variadic for mapping over multiple sequences in parallel - The
minandmaxcommands now accept an index for more efficient evaluation rethinkdb exportnow exports secondary index information andrethinkdb importre-creates exported indexeskqueueis now used instead ofpollfor dramatically better performance on OS X
For a full list of over 300 improvements, see the changelog.
Next steps
See the full list of enhancements, and take the new release for a spin!
The team is already hard at work on the upcoming 2.0 release. The 2.0 release will focus on operational and API stability, and will be the first production-ready release of RethinkDB. As always, if there is something you’d like us to prioritize or if you have any feedback on the release, please let us know.
Help work on the 2.0:release: RethinkDB is hiring.